My GPS logger is capturing lots of useful information but it's difficult to efficiently capture data for regular activities. Geotagging photos is easy, and manually working with the logs for a special event is possible, but it's not feasible to put in that much work to analyze commutes for example.
The logger creates a separate log file each time it's switched on and off, and while these logs could be sorted into categories for analysis, it's easy to forget to turn it on and off at the start and end of a section of interest and activities are then merged in the logs. In addition, there is often "junk" data at start and end of logs while leaving or arriving at a destination.
I wanted to be able to automatically capture the information about my daily activities by simply switching on the logger and carrying it around with me. I then simply want to plug the logger into the computer and have the logs automatically chopped into segments of interest that can be compared to each other over time.
The rest of this post roughly outlines the Python script I created to perform this task, minus some of the hopefully irrelevant details.
Firstly, I collect the lat/long coordinates of places that I am interested in collecting data while I'm there and traveling between them. These include my home, work, the climbing gym and so on. Each point has a radius within which any readings will be considered to be in that place.
# id: name lat long radius
places = { 1: ("A", -37.123456, 145.123456, 0.050),
2: ("B", -37.234567, 145.234567, 0.050),
3: ("C", -37.345678, 145.345678, 0.050) }
otherid = 4
For each of these places of interest, I then use gpsbabel's radius filter to find all the times where I was within that zone:
# create a list of all raw log files to be processed
from path import path
month = path("/gpslogs/200808")
logs = " ".join(["-i nmea -f %s"%log
for log in sorted((month/"raw").files("GPS_*.log"))])
for (id,(place,lat,lon,radius)) in places.items():
os.system("gpsbabel "
# input files
+ logs
# convert to waypoints
+ " -x transform,wpt=trk,del"
# remove anything outside place of interest
+ (" -x radius,distance=%.3fK,lat=%.6f,lon=%.6f,nosort"%(radius,lat,lon))
# convert back to tracks
+ " -x transform,trk=wpt,del"
# output nmea to stdout
+ " -o nmea -F -"
# filter to just GPRMC sentences
+ " | grep GPRMC"
# output to log file
+ (" > %s/processed/place%d.log"%(month,id)))
And all points outside any of the specific places of interest are sent into an "other" file:
os.system("gpsbabel "
# input files
+ logs
# convert to waypoints
+ " -x transform,wpt=trk,del"
# remove anything in a place of interest
+ "".join([" -x radius,distance=%.3fK,lat=%.6f,lon=%.6f,nosort,exclude"%(radius,lat,lon)
for (id,(place,lat,lon,radius)) in places.items()])
# convert back to tracks
+ " -x transform,trk=wpt,del"
# output nmea to stdout
+ " -o nmea -F -"
# filter to just GPRMC sentences
+ " | grep GPRMC"
# output to log file
+ (" > %s/processed/place%d.log" % (month, otherid)))
These files are filtered with grep to contain only minimal data as we only require the timestamps for this part of the process. Specifically only the NMEA GPRMC sentences are kept.
To provide a brief illustration, the following picture shows two log files of data, a blue and a green, between three points of interest:
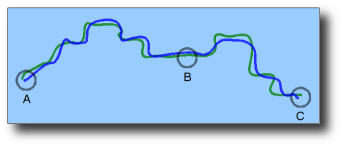
The above process would create four files, one for each point A, B and C and one for "Other" points that would contain something like the following information, where the horizontal axis represents time:

I then read all those log files back in to create a "time line" that for each timestamp stores my "location" in the sense that it knows whether I was "home", at "work" or somewhere between the two.
# dict of timestamp (seconds since epoch, UTC) to placeid
where = {}
for placeid in places.keys()+[otherid,]:
for line in (month/"processed"/("place%d.log"%placeid)).lines():
fields = line.split(",")
# convert date/time to seconds since epoch (UTC)
t, d = fields[1], fields[-3]
ts = calendar.timegm( (2000+int(d[4:6]), int(d[2:4]), int(d[0:2]),
int(t[0:2]), int(t[2:4]), int(t[4:6])) )
where[ts] = placeid
This is then summarised from one value per second to a list of "segments" with a start and end time and a location. Unlogged time segments are also inserted at this point whenever there are no logged readings for 5 minutes or more.
# array of tuples (placeid, start, end, logged)
# placeid = 0 indicates "unknown location", i.e. unlogged
summary = []
current, start, stop, last_ts = 0, 0, 0, None
for ts in sorted(where.keys()):
# detect and insert "gaps" if space between logged timestamps is greater than 5 minutes
if last_ts and ts-last_ts > 5*60:
if current:
summary.append( [current, start, stop, True] )
current, start, stop = where[ts], ts, ts
summary.append( [0, last_ts, ts, False] )
last_ts = ts
if where[ts] != current:
if current:
summary.append( [current, start, stop, True] )
current, start, stop = where[ts], ts, ts
else:
stop = ts
summary.append( [current, start, stop, True] )
(If there's a more "Pythonic" way of writing that kind of code, I'd be interested in knowing it.)
"Spurious" segments are then removed. These show up because when the logger is inside buildings the location jumps around and often out of the 50m radius meaning that, for example, there will be a sequence of Home-Other-Home-Other-Home logs. The "Other" segments that are between two known points of interest and less than 5 minutes long are deleted, as are "Other" segments that sit between a known place of interest and an unlogged segment.
Based on the above graphic, the summary might look something like the following:
| start | end | location |
|---|
| 10.00am | 10.05am | A |
| 10.05am | 10.30am | Other |
| 10.30am | 10.35am | B |
| 10.35am | 11.00am | Other |
| ... |
The "Other" segments are then labelled if possible to indicate they were "commutes" between known locations:
| start | end | location |
|---|
| 10.00am | 10.05am | A |
| 10.05am | 10.30am | A-B |
| 10.30am | 10.35am | B |
| 10.35am | 11.00am | B-C |
| ... |
Some segments cannot be labeled automatically and are left as "Other". This may be a trip out to a "one-off" location and back again, which can be left as "Other". However, sometimes it is because the logger didn't lock onto the satellites within the 50m radius on the way out of a place of interest and these can be manually fixed up later.
Once a list of "activities" has been obtained, with start and end times, it is easy to use gpsbabel again to split logs based on start and end of time segments:
for (place, start, stop, place_from, place_to, logged) in summary:
dest = month / "processed" / ("%s-%s"%(time.strftime("%Y%m%d%H%M%S", time.localtime(start)),
time.strftime("%Y%m%d%H%M%S", time.localtime(stop))))
for (ext, chopFn) in [(".log", chopToLog),
(".kml", chopToKml),
(".speed", chopToSpeedVsDistance),
(".alt", chopToAltitudeVsDistance),
(".hist", chopToSpeedHistogram),
(".head", chopToHeadingHistogram),
(".stops", chopToStopsVsDistance)]:
if not (dest+ext).exists():
chopFn(dest, locals())
# make the file in case it was empty and not created
(dest+ext).touch()
This generates a bunch of files for each segment, named with the start and end timestamps of the segment and an extension depending on the content. The first "chop" function generates an NMEA format log file that is then processed further by the remaining "chop" functions. The other chop functions will probably be explained in a later post, the first two are:
def chopToLog(dest, p):
# filter input file entries within times of interest to temp file
os.system("gpsbabel " + p["logs"]
+ (" -x track,merge,start=%s,stop=%s"
% (time.strftime("%Y%m%d%H%M%S", time.gmtime(p["start"])),
time.strftime("%Y%m%d%H%M%S", time.gmtime(p["stop"]))))
+ " -o nmea -F "+sh_escape(dest)+".log")
def chopToKml(dest, p):
# create kml file with reduced resolution
os.system("gpsbabel -i nmea -f "+sh_escape(dest)+".log"
+ " -x simplify,error=0.01k"
+ " -o kml -F "+sh_escape(dest)+".kml")
def sh_escape(p):
return p.replace("(","\\(").replace(")","\\)").replace(" ","\\ ")
(Again, if there's a better way to handle escaping special characters in shell commands, I would like to know it.)
Using this, I can simply plug in the logger, which launches an autorun script, and the end result are nicely segmented log files that I can map and graph. More about that in another post.



